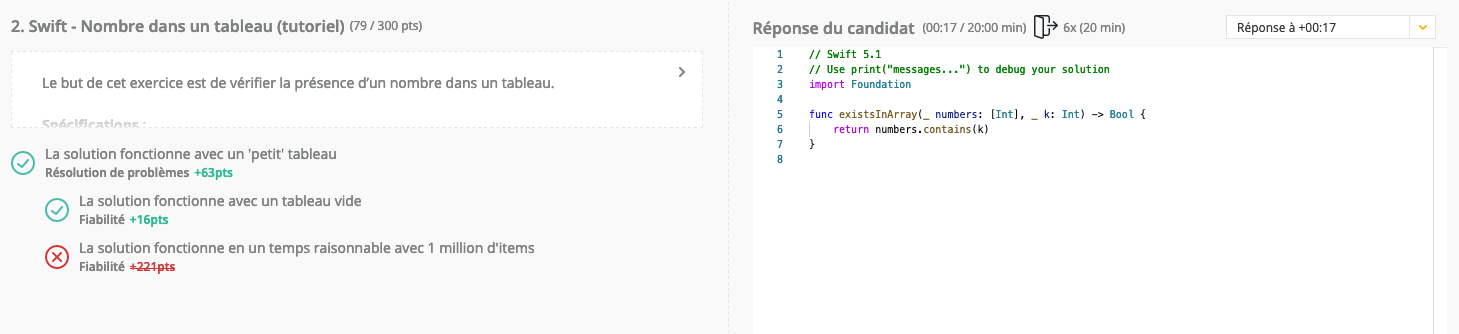
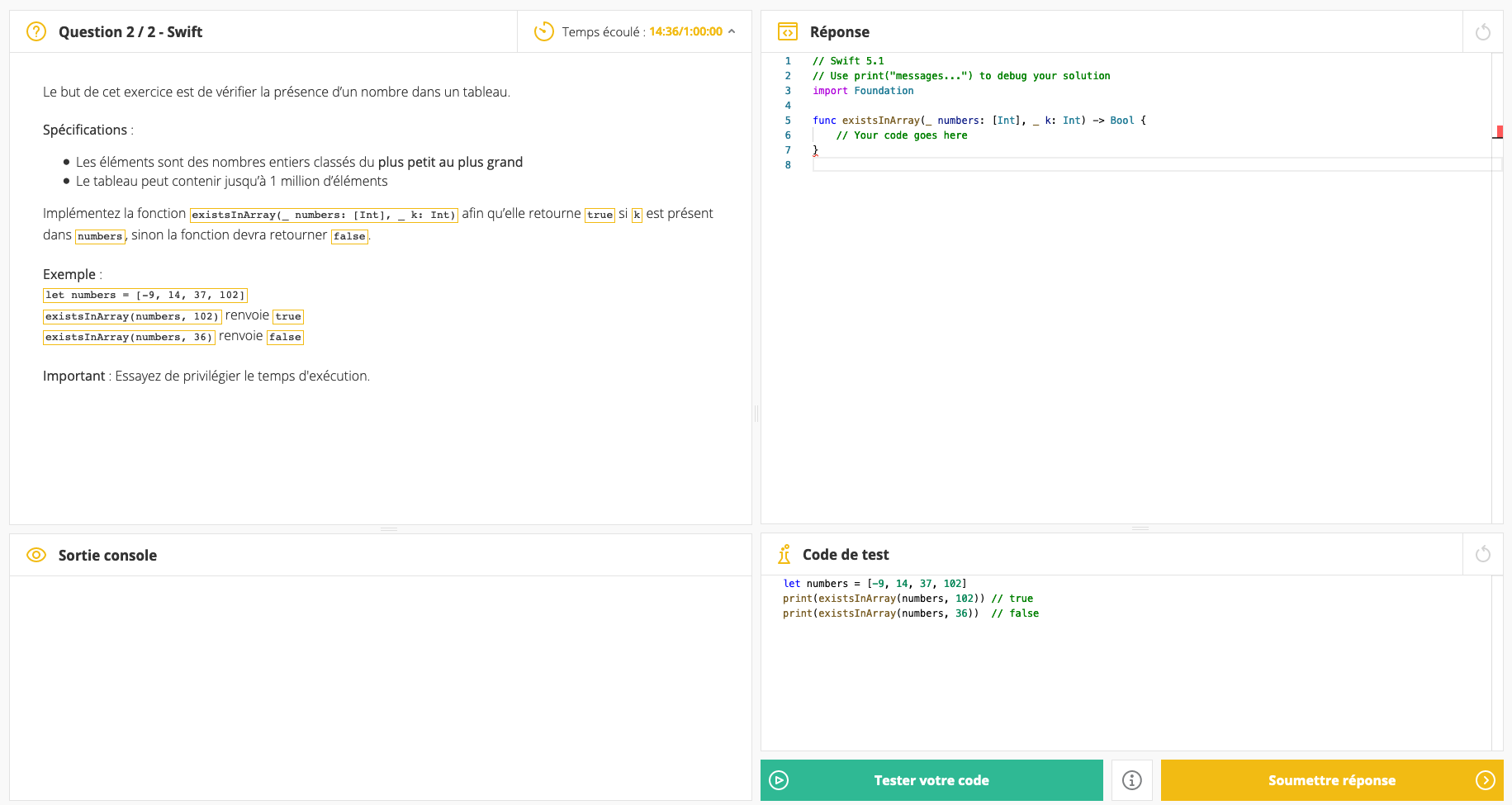
J’ai passé un petit test en ligne, pour connaitre mes compétences en Swift, et je devais implémenter une fonction qui prend en paramètre un Array et un Int
Elle retourne true si le Int est dans le tableau, et false sinon
Ma question c’est comment faire pour que ça soit le plus rapide possible ?
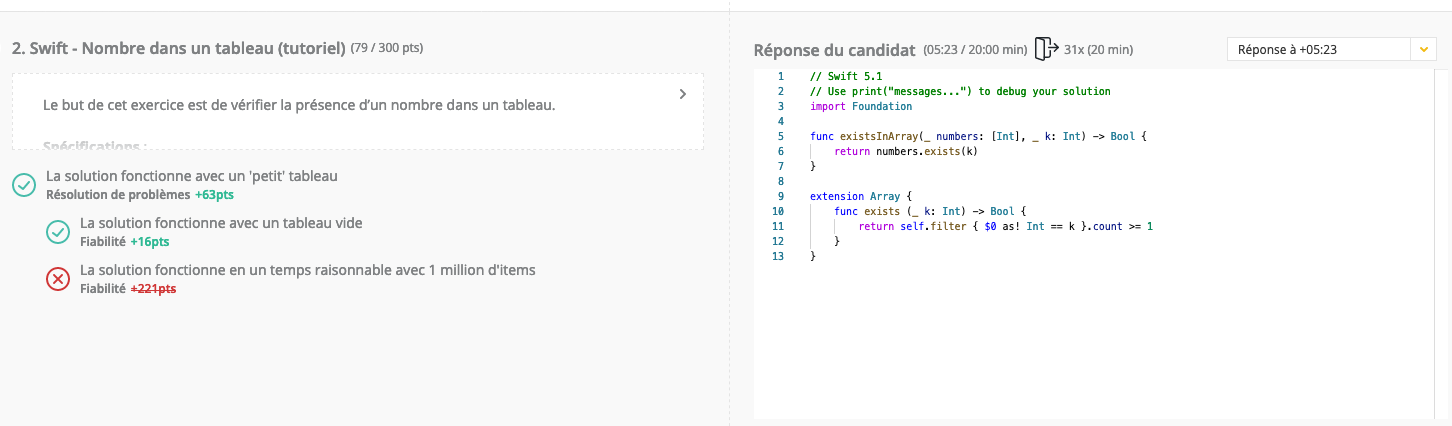
En faisant des recherches, je suis tombé sur une réponse de stackoverflow, qui parle d’utiliser un Set au lieu d’un Array, c’était super intéressant car je ne connaissais pas Set en Swift
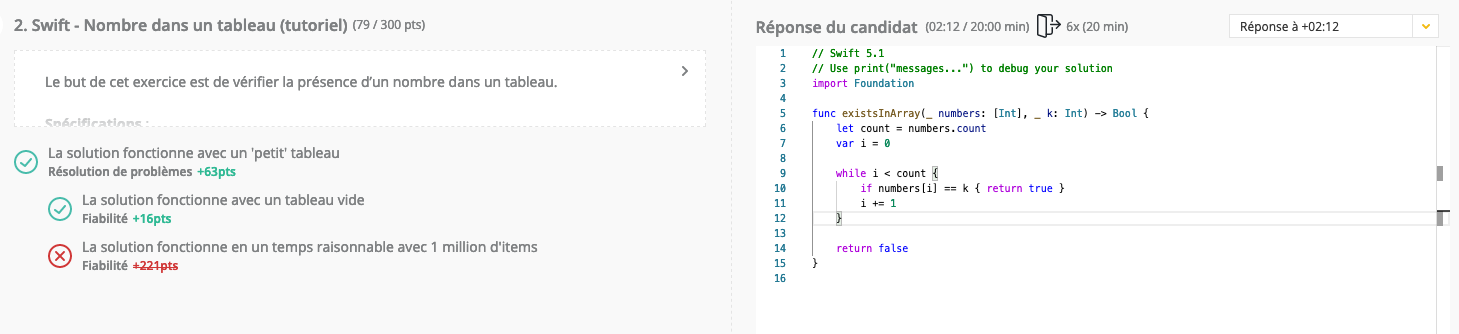
Essaye en créant une extension de Array. Le problème des fonctions, c’est que les données sont copiées au moment de l’exécution. Tu ne travailles pas sur le tableau lui-même, mais sur une copie.
Il est possible que l’extension travaille sur le tableau lui-même et non un double, ce qui évite la phase duplication des données et fait gagner du temps. A tester.
Je ne suis pas surpris que le Set pose problème. C’est un ensemble de données triées avec des clés de recherche, pour une vérification rapide. Mais UN MILLION DE DONNEES TRIEES c’est vraiment beaucoup.
Ta manière de montrer du code dans une copie d’écran n’est pas pratique. Tu devrais plutôt insérer le code dans le texte, comme nous le faisons tous, ici …
A mon avis le système de réponse automatique est bugé !
Il y a des informations supplémentaires sur le tableau de départ ? Est-il déjà trié par ordre croissant ?
Idéalement si tu pouvait copier coller l’énoncé ce serait super
Je reçois un lien avec un token unique, et je dois résoudre les exercices dans un temps déterminé.
La fonction copier-coller est désactivé dans le navigateur, de ce fait je peux seulement faire une capture d’écran.
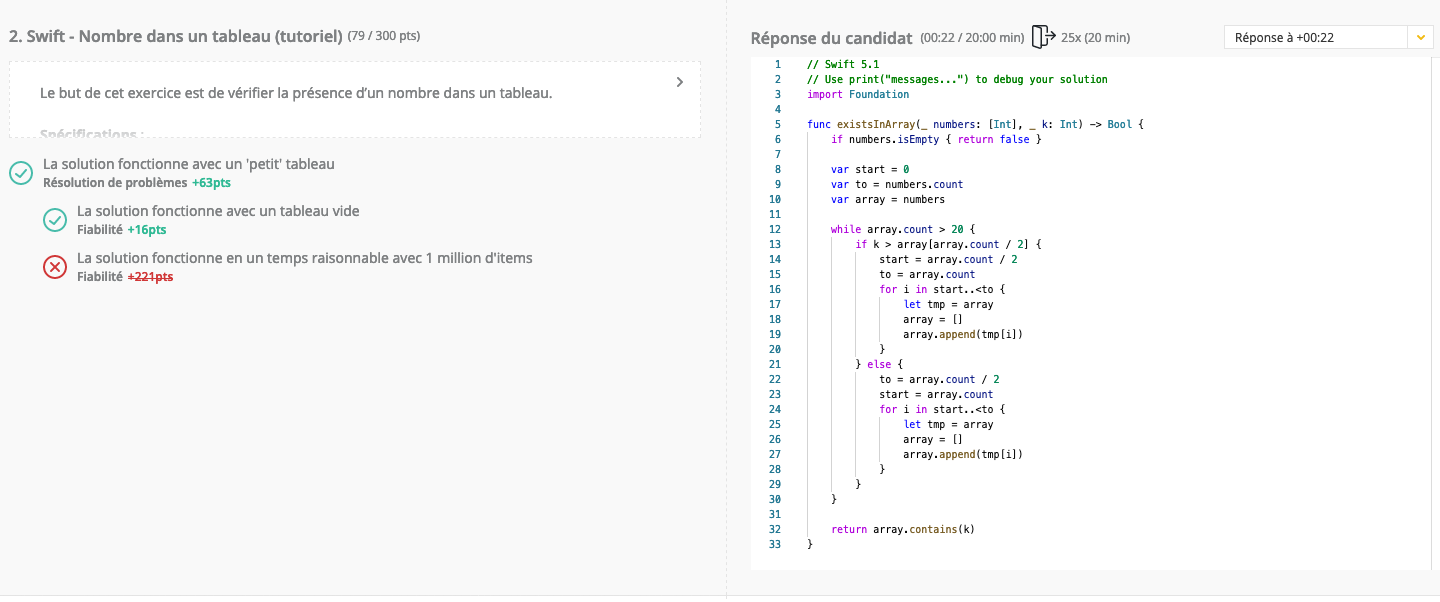
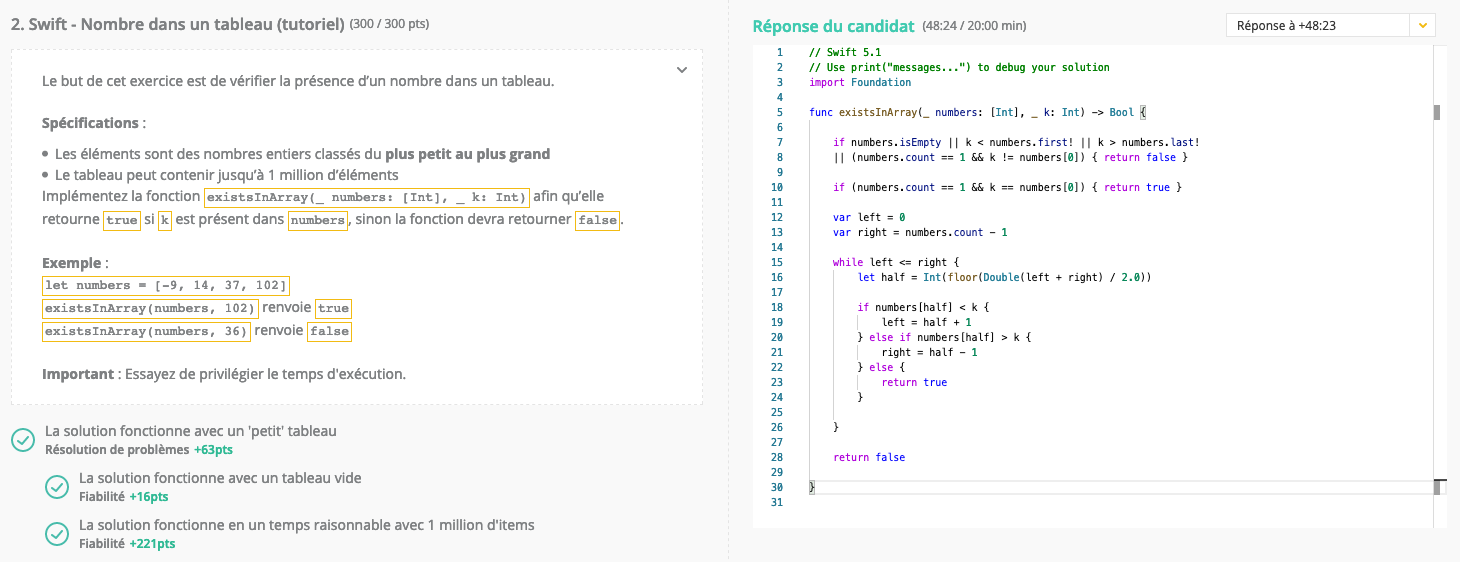
@mbritto oui c’est un tableau trié. J’ai essayé la dichotomie, qui consiste à diviser le tableau en deux, et créer un autre tableau avec le sous-tableau précédent qui contient la valeur recherchée. Et trop lent également …
Ah, mais ça change tout, si le tableau est déjà trié. C’est effectivement une recherche dichotomique qu’il faut faire, mais pas en créant de nouveaux tableaux. Il faut juste faire une recherche sur l’index, avec affinement progressif de la localisation. Quelque chose comme : -
Tu regardes le contenu de la dernière case du tableau. Si c’est inférieur à la valeur recherchée, pas de solution => return false
Si c’est supérieur, tu regardes la valeur de la case située au milieu du tableau, pour réduire la recherche à la partie supérieure et inférieure. Et tu continues le processus en réduisant à chaque fois la zone de recherche par deux, jusqu’à trouver la bonne valeur. C’est très rapide, même avec un tableau d’un million d’items, puisque tu élimines 50% du tableau à chaque itération de la boucle.
Evidement, c’est lent de créer un nouveau tableau en mémoire, surtout s’il contient 1 million d’objets ! Alors que la lecture d’une case à partir d’un index est quasi-instantanée.
Effectivement, quand j’avais la tête dans le code, j’avais pas forcément la meilleure approche. Maintenant avec du recul, il est vrai que c’est inutile de créer un autre tableau, il aurait suffit de travailler avec les index.
Malheureusement, mon temps était compté, fallait que je fasse vite : 20 min c’est trop peu quand tu n’as pas l’habitude …
Vous savez où je pourrais trouver des cours d’algo pour ne plus refaire cette erreur ?
Je connais déjà le Swift Algorithm Club, mais ce qui me gêne c’est que je n’ai pas la possibilité de tester si l’algo est assez rapide sur de gros tableaux (comme celui d’1 million) … il faudrait un compilateur en ligne ou un programme qui te dit combien de temps a mis le code pour retourner une valeur …
D’ailleurs @mbritto voici une idée pour de futurs cours: pourquoi pas des exercices d’algo comme la recherche d’un élément dans un tableau (selon s’il est trié ou pas), tri des tableaux dans un temps défini, etc …
EDIT: voici l’exercice avec l’ennoncé au complet :
Je pense à un truc, je ne sais pas du tout si ça aiderait, ou si c’est une bonne idée, mais en faisant appel au multithreading, en coupant ton tableau en plusieurs section chacune testée dans un thread concurrent pour parvenir au résultat un peu plus vite ? (combien de threads faudrait-il, idéalement, sur un tableau d’un million, pour que leur exécution soit plus rapide et contrebalance la perte de temps de la mise en œuvre ?)